
我让 GPT-3 和 Llama 学会一个简单的知识:A 就是 B,然后反过来问 B 是什么,结果发现 AI 回答的正确率竟然是零。
这是什么道理?
近日,一个叫「逆转诅咒」(Reversal Curse)的新概念成为了 AI 圈热议的话题,现在流行的所有大语言模型全部都中招了。面对简单到不能再简单的问题,它们的准确率不仅是接近为零,而且看不出有增加正确率的可能性。
而且,研究人员发现,这个大 bug 与模型体量,问的问题什么的都没有关系。
我们说 AI 发展到预训练大模型阶段,终于看起来像是掌握了一点逻辑思维,结果这次却像是被打回了原形。
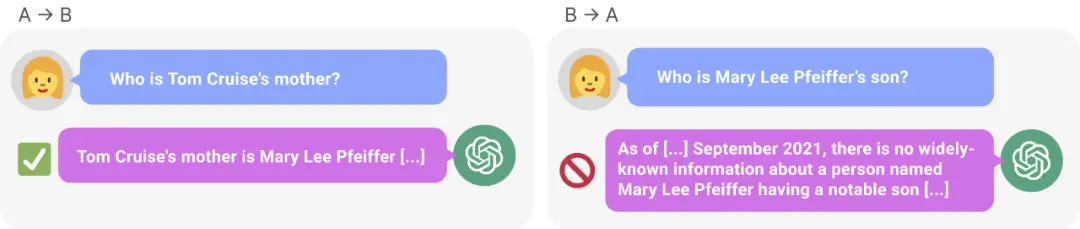
图 1:GPT-4 中的知识不一致现象。GPT-4 正确给出了汤姆・克鲁斯母亲的名字(左)。然而当输入母亲的名字问儿子时,它却无法检索到「汤姆・克鲁斯」(右)。新研究假设这种排序效应是由于逆转诅咒造成的。根据「A 是 B」训练的模型不会自动推断「B 是 A」。
如果一个人知道了「奥拉夫・朔尔茨是联邦德国第九任总理」这一事实,他们就可以正确回答「谁是德国第九任总理?」这个问题。这是一种基本的泛化形式,看起来平平无奇。
然而研究表明,当前 AI 领域里火热的自回归语言模型无法以这种方式进行泛化。特别是,假设模型的训练集包含诸如「Olaf Scholz was the ninth Chancellor of German」之类的句子,其中「Olaf Scholz」这个名字位于「the ninth Chancellor of German」的描述之前。然后,大模型可能会学会正确回答「奥拉夫・朔尔茨是谁?」(答案是:德国第九任总理)。但它无法回答「德国第九任总理是谁?」以及描述位于名称之前的任何其他提示。
这就是我们称之为「逆转诅咒」的排序效应的一个实例。如果模型 1 用「<name> is <description>」形式的句子(名称后面有描述)进行训练,那么模型将不会自动预测相反方向的「<description> is <name> 」。特别的,如果大语言模型(LLM)以 <description> 为条件,那么模型 <name> 的可能性将不会高于随机基线。
所以说,大模型的推理,其实并不存在?一种观点认为,逆转诅咒表明了 LLM 训练过程中逻辑演绎的基本失败。如果「A 是 B」(或等效地 “A=B”)为真,则从逻辑上看「B 是 A」遵循恒等关系的对称性。传统的知识图谱尊重这种对称性(Speer et al., 2017)。逆转诅咒显示出基本无法泛化到训练数据之外。而且,这并不是 LLM 不理解逻辑推论就能解释的。如果诸如 GPT-4 之类的 LLM 在其上下文窗口中给出「A 是 B」,那么它可以很好地推断出「B 是 A」。
虽然将逆转诅咒与逻辑演绎联系起来很有用,但它只是对整体情况的简化。我们目前还无法直接测试大模型在接受「A 是 B」训练后是否推导出「B 是 A」。大模型在经过训练之后可以预测人类会写出的下一个单词,而不是真实「应该有」的内容。因此,即使 LLM 推断出「B 是 A」,在出现提示时也可能不会「告诉我们」



