华为诺亚方舟实验室开源了一批优秀预训练语言模型,性能更好、使用更方便。
昨日,华为诺亚方舟实验室的 NLP 团队开源了两个重要的预训练语言模型——哪吒和 TinyBERT。这两个模型可以直接下载、预训练和微调。华为语音语义首席科学家刘群在微博上转发了这一消息。

项目地址:https://github.com/huawei-noah/Pretrained-Language-Model
根据 GitHub 上的介绍,这一项目是诺亚方舟实验室用来开源各种预训练模型的项目,目前有两个,日后不排除有更多模型加入进来。
哪吒模型
该项目中第一个开源的模型是哪吒(NEZHA:NEural contextualiZed representation for CHinese lAnguage understanding),是华为诺亚方舟实验室自研的预训练语言模型,在一些 NLP 任务上取得了 SOTA 的表现。这一模型基于 BERT,可以在普通的 GPU 集群上进行训练,同时融合了英伟达和谷歌代码的早期版本。

在今年的智源大会上,刘群介绍了哪吒模型的相关工作。
哪吒是一个基于 BERT 进行优化和改进的预训练语言模型,中文采用的语料是 Wikipedia 和 Baike 和 News,而谷歌的中文语料只用了 Wikipedia。英文的哪吒采用的是 Wikipedia 和 BookCorpus,跟中文一样。
哪吒在训练过程中采用了华为云,能够实现多卡多机训练。当然,本次发布的哪吒和华为的版本有些不同,可以在一般的 GPU 上训练。此外,哪吒还采用了英伟达的混合精度训练方法,本次项目开源的时候也公开了。
预训练过程
模型的使用方法和 BERT 类似。首先,用户需要准备数据,方法和 BERT 准备数据的过程类似:
在训练过程中,用户需要准备 horovod 分布式训练环境,然后运行 script 文件夹中的 run_pretraining.sh 文件即可。
微调过程
目前,哪吒模型支持三种任务上的微调:文本分类、序列标注和类似 SQuAD 的机器阅读理解,微调的相关代码基于谷歌的相关代码。
预训练过程如下:
下载预训练模型,解压模型文件、词汇文件和配置文件到文件夹「nezha」中;
建立微调任务,根据任务不同运行不同的脚本:
scripts/run_clf.sh 脚本用于文本分类任务,如 LCQMC、ChnSenti 和 XNLI;
scripts/run_seq_labelling.sh 脚本用于序列标注任务,如 Peoples-daily-NER;
scripts/run_reading.sh 脚本用于机器阅读理解任务,如 CMRC 2018;
从相关输出位置获得结果。
需要注意的是,CMRC 任务的评估稍有不同,需要运行以下代码:
以上任务需要的文件都保存在了项目文件夹中。
哪吒模型已经可以下载,已有四种中文的预训练模型,分别是 base、large 和对应的 mask 和全词 mask 类型。
下载地址:https://pan.baidu.com/s/1V7btNIDqBHvz4g9LOPLeeg
密码:x3qk
TinyBERT
本项目开源的另一个模型是 TinyBERT,这是一个通过蒸馏方法获得的 BERT 模型。
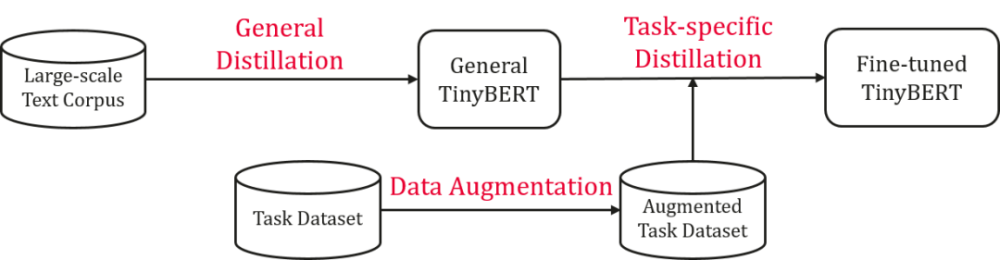
TinyBERT 的建模过程。
相比原版的 BERT-base,TinyBERT 比它小了 7.5 倍,推理速度则快了 9.4 倍。无论是在预训练阶段还是特定任务学习阶段,TinyBERT 的性能都更好。
使用方法
TinyBERT 的使用方法和哪吒项目有所不同,它分为三个步骤:蒸馏、数据增强以及特定任务蒸馏。
1. 蒸馏
在第一个蒸馏阶段,研究者需要使用原版的 BERT-base(没有微调的版本)作为教师模型、通过 Transformer 蒸馏的方法,可以获得一个泛化的 TinyBERT 模型。之后再进行特定任务蒸馏。
泛化蒸馏有两个步骤:生成 json 形式的语料,然后进行蒸馏。
第一步,使用 use pregenerate_training_data.py 文件,生成语料。
第二步,使用 use general_distill.py 进行蒸馏。
在项目中,研究者提供了已蒸馏过的 TinyBERT 模型。
2. 数据增强
数据增强是一个能够扩展特定任务中训练集的方法。通过学习更多任务相关的样本,学生模型的泛化能力可以进一步提升。研究者在数据增强阶段结合了 BERT 和 GloVe 的方法,进行词级别的替换,以此来增强数据。
在这里,用户可以使用 data_augmentation.py 文件进行数据增强。增强后的数据集文件会自动保存在对应的 $$ 中。
在运行 GLUE 任务中的数据增强代码前,你需要下载 GLUE 数据,并解压文件到 GLUE_DIR 中。在命令行中,TASK_NAME 可以是 GLUE 任务中的 CoLA、SST-2、MRPC、STS-B、QQP、MNLI、QNLI 和 RTE。
3. 特定任务蒸馏
这一阶段主要对 transformer 进行进一步蒸馏,以提升在特定任务上的性能。这一阶段分两步:首先进行中间层蒸馏,然后进行预测层蒸馏。
运行 task_distill.py 即可进行中间层蒸馏。
之后运行 task_distill.py 即可进行预测层蒸馏。
模型性能评估
TinyBERT 的模型性能评估使用的是单独的代码,运行 task_distill.py 即可。
安装方法
对于 TinyBERT,用户需要下载专门的模型,安装相关依赖(基于 Python3):
模型分为以下几种:
1. 没有特定任务蒸馏的泛化模型:
论文复现版本:
General_TinyBERT(4layer-312dim)
下载地址:https://drive.google.com/uc?export=download&id=1dDigD7QBv1BmE6pWU71pFYPgovvEqOOj
General_TinyBERT(6layer-768dim)
下载地址:https://drive.google.com/uc?export=download&id=1wXWR00EHK-Eb7pbyw0VP234i2JTnjJ-x
第二版 (2019/11/18) 使用更多数据、无 [MASK] 语料版本:
General_TinyBERT_v2(4layer-312dim)
下载地址:https://drive.google.com/open?id=1PhI73thKoLU2iliasJmlQXBav3v33-8z
General_TinyBERT_v2(6layer-768dim)
下载地址:https://drive.google.com/open?id=1r2bmEsQe4jUBrzJknnNaBJQDgiRKmQjF
2. GLUE 任务上蒸馏后的模型
每个任务对应一个模型,这些模型可以使用之前提供的评估代码进行评估:
TinyBERT(4layer-312dim)
下载地址:https://drive.google.com/uc?export=download&id=1_sCARNCgOZZFiWTSgNbE7viW_G5vIXYg
TinyBERT(6layer-768dim)
下载地址:https://drive.google.com/uc?export=download&id=1Vf0ZnMhtZFUE0XoD3hTXc6QtHwKr_PwS
项目作者表示,之后他们会测试 TinyBERT 在中文任务上的表现、尝试使用哪吒或 ALBERT 作为教师模型进行蒸馏,以及公开性能更好的模型等。