没想到时至今日,ChatGPT竟还会犯低级错误?
吴恩达大神最新开课就指出来了:
ChatGPT不会反转单词!
比如让它反转下lollipop这个词,输出是pilollol,完全混乱。

哦豁,这确实有点大跌眼镜啊。
以至于听课网友在Reddit上发帖后,立马引来大量围观,帖子热度火速冲到6k。
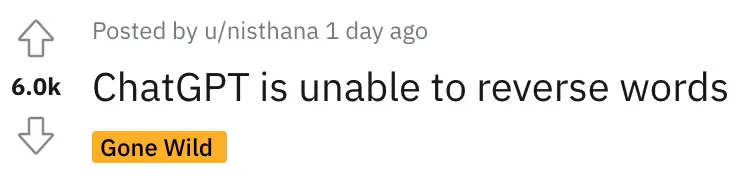
而且这不是偶然bug,网友们发现ChatGPT确实无法完成这个任务,我们亲测结果也同样如此。
甚至包括Bard、Bing、文心一言在内等一众产品都不行。还有人紧跟着吐槽, ChatGPT在处理这些简单的单词任务就是很糟糕。
比如玩此前曾爆火的文字游戏Wordle简直就是一场灾难,从来没有做对过。诶?这到底是为啥?
01 关键在于token
之所以有这样的现象,关键在于token。token是文本中最常见的字符序列,而大模型都是用token来处理文本。
它可以是整个单词,也可以是单词一个片段。大模型了解这些token之间的统计关系,并且擅长生成下一个token。
因此在处理单词反转这个小任务时,它可能只是将每个token翻转过来,而不是字母。这点放在中文语境下体现就更为明显:一个词是一个token,也可能是一个字是一个token。针对开头的例子,有人尝试理解了下ChatGPT的推理过程。比如像lollipop这个词,GPT-3会将其理解成I、oll、ipop这三个部分。
根据经验总结,也就诞生出这样一些不成文法则。
1个token≈4个英文字符≈四分之三个词;
100个token≈75个单词;
1-2句话≈30个token;
一段话≈100个token,1500个单词≈2048个token;
单词如何划分还取决于语言。此前有人统计过,中文要用的token数是英文数量的1.2到2.7倍。