让ChatGPT给出答案之前多想想步骤,就能提高准确率。
那么能不能省去提示词,直接把这种能力内化在大模型里呢?
CMU与谷歌团队的新研究,在训练大模型时加入暂停token来实现这一点。
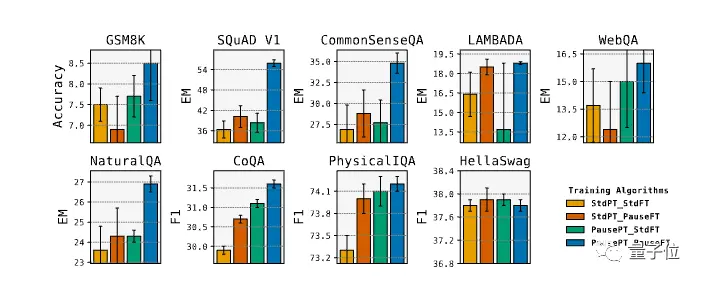
实验中,8项评测成绩提升,其中SQuAD的EM得分提高18%,CommonSenseQA提高8%,GSM8k中的推理任务也提高1%。
研究者Jack Hack表示,自己不久前就提出类似假设,很高兴看到它被验证。
英伟达工程师Aaron Erickson表示,是不是和人类说话时加入“嗯嗯啊啊”是一个道理?
预训练微调都加入暂停token
整个研究基于一个简单的想法:
在输入序列后面追加一系列(暂停token),从而延迟模型输出下一个token。
这可以给模型额外的计算时间来处理更复杂的输入。
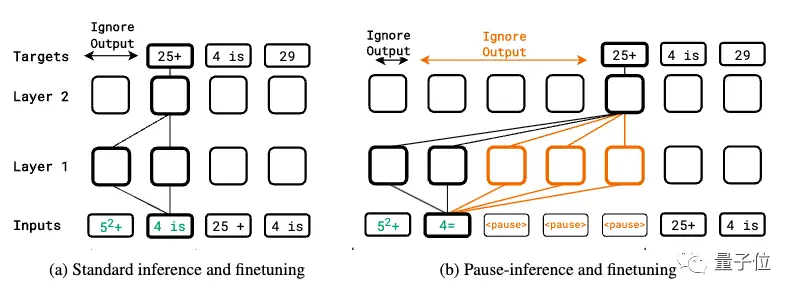
作者不仅在下游任务微调时引入,还在预训练时就随机在序列中插入,让模型在两阶段都学习如何利用这种计算延迟。